Všichni jsme ty rady při psaní odborných článků slyšeli stokrát: „Pište jednoduše. Buďte struční. Nepoužívejte zbytečný žargon.“ Jenže co když hodnotitelé – a v budoucnu stále častěji i algoritmy – ve skutečnosti oceňují pravý opak? „Náš tým na Fakultě informatiky a statistiky VŠE se rozhodl vyměnit dojmy za data,“ píše v komentáři Tomáš Kliegr z Vysoké školy ekonomické v Praze.
Ve studii publikované v časopise Machine Learning testujeme metodu, která se snaží otevřít „černou skříňku“ umělé inteligence a zjistit, co odlišuje špičkové články od průměrných.
Jak naučit AI vysvětlovat? (Metodika)
Základní myšlenka našeho experimentu byla prostá. Většina současných AI modelů pro analýzu textu (např. BERT) funguje neprůhledně – text převedou na složitá čísla, která jsou pro člověka nečitelná. My jsme zvolili jinou cestu. Využili jsme velké jazykové modely (LLM, konkrétně Llama 2 a GPT-4) nikoliv jako soudce, ale jako inteligentní „čtenáře“.
Modelům jsme zadali úkol extrahovat z textu srozumitelné rysy (vlastnosti; anglicky features). Ptali jsme se na konkrétní věci: Je metodologie rigorózní? Obsahuje text statistickou analýzu? Je jazyk komplexní? Získali jsme tak strukturovaná data, nad nimiž jsme trénovali transparentní klasifikační modely. Tento postup (LLM-based feature generation) nám umožnil nahlédnout do toho, co může hrát roli v hodnocení. Ve druhém experimentu jsme šli ještě dál: nechali jsme modely navrhnout i to, které rysy jsou pro hodnotitele podstatné. Výsledky shrnuje další část.
Laboratoř jménem M17+
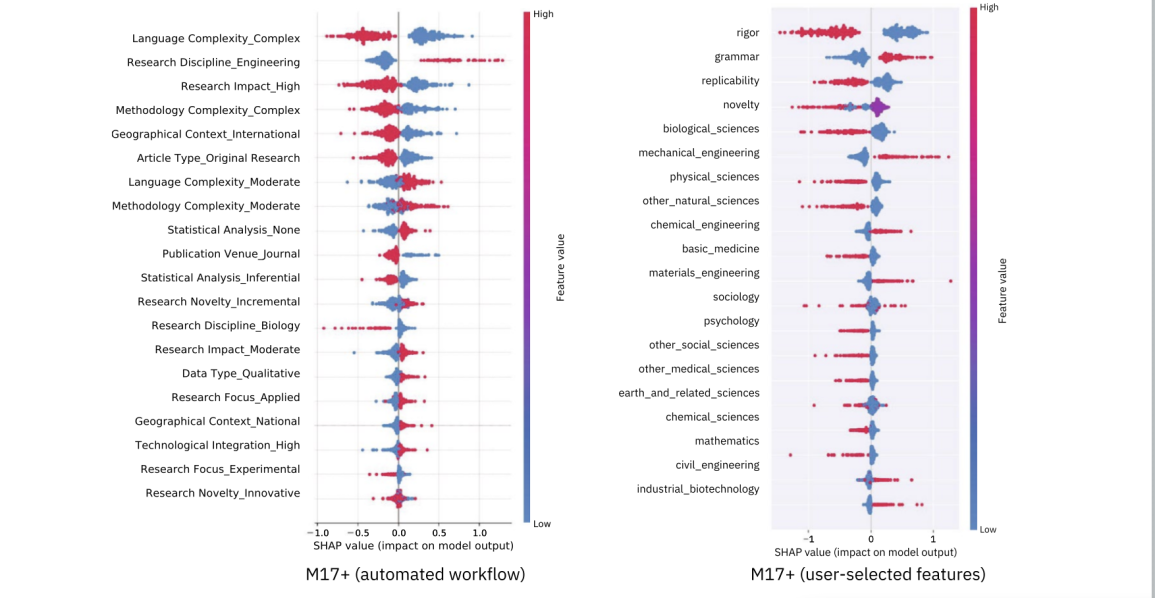
Jako hlavní testovací pole jsme použili data z českého hodnocení výzkumných organizací podle Metodiky 17+ (Modulu 1). Využili jsme veřejně dostupné abstrakty článků obodované expertními panely. Pracovali jsme s vyváženým datasetem 2 000 abstraktů, rovnoměrně rozdělených podle výsledné známky (od špičkové kvality po průměr/ podprůměr).
Zajímalo nás, které rysy textu nejvíce souvisejí s výslednou známkou. V úvodu tohoto článku uvedený graf Shapleyho hodnot (SHAP) ukazuje, co mělo na predikci modelu největší vliv.
Pohled na data přináší pro zastánce jednoduchosti možná trochu překvapivá zjištění:
- Paradox složitosti: U rysu Language Complexity_Complex jsou červené body výrazně vlevo. Texty, které LLM vyhodnotil jako jazykově komplexní a hutné, měly vyšší šanci na špičkové hodnocení než ty psané jednoduše. V prostředí M17+ může odborný styl fungovat jako signál kvality.
- Statistika je nutnost: Absence statistické analýzy (Statistical Analysis_None; červené body vpravo) článek penalizuje.
- Sebevědomí se vyplácí: Research Impact_High (vysoký dopad výzkumu) táhne hodnocení k lepším známkám.
- Oborové nuance: Vzorek naznačuje i rozdíly mezi disciplínami – například biologie (Research Discipline_Biology) měla mírnou výhodu oproti inženýrským oborům (Engineering).
Je třeba zdůraznit, že model identifikuje statistické souvislosti, které nemusí nutně znamenat příčinnou souvislost (kauzalitu).
Cena za srozumitelnost a univerzální použitelnost
Nabízí se otázka, zda „průhlednost“ není vykoupena ztrátou přesnosti. Když jsme náš přístup porovnali s TF-IDF a se SciBERT (neprůhledný „black-box“ model, u kterého je obtížné vysvětlit jednotlivá rozhodnutí), výsledky byly povzbudivé: dosahovali jsme srovnatelného výkonu jako SciBERT a často jsme překonávali jednodušší metody. Jinými slovy: náš model dosahuje podobně dobrých výsledků jako výrazně složitější přístupy, ale zároveň je lépe pochopitelné, jak k těmto výsledkům dospěl. Ukazuje se, že lze být konkurenceschopní bez obětování vysvětlitelnosti.
Abychom ověřili přenositelnost metody, otestovali jsme ji na pěti velmi odlišných datasetech: vedle hodnocení vědy a medicínských textů (CORD-19) také na třídění bankovních dotazů (Banking77), detekci nenávistných projevů (Hate Speech) i na datasetu Food Hazard (hlášení o nebezpečných potravinách). Model se adaptoval bez složitého přeučování: místo metodiky či novosti začal sledovat rysy jako typ toxinu, alergeny nebo závažnost kontaminace. To podporuje závěr, že extrakce sémantických rysů je využitelná napříč doménami.
Závěrem: Jednoduchost, která otevírá dveře
Kouzlo přístupu je v přímočarém postupu, který si může vyzkoušet každý. Proces má tři kroky: vezmete text, ukážete ho jazykovému modelu s několika příklady, aby sám navrhl relevantní rysy (tzv. feature discovery), a pak necháte model tyto hodnoty v datech vyplnit. Získáte strukturovaná data připravená pro transparentní („white-box“) metody, například rozhodovací stromy. Výsledkem není jen predikce, ale i hlubší vhled do toho, co rozhoduje.
Plný text článku je po omezenou dobu dostupný pod tímto odkazem: https://rdcu.be/eIXYH.
Při přípravě tohoto popularizačního článku byly konzultovány nástroje umělé inteligence.